“Se vuoi capire un dispositivo davvero complesso, come un cervello, dovresti costruirne uno.”
G. Hinton, 2018.
Lo sviluppo delle moderne reti neurali artificiali è avvenuto attraverso una serie di progressi graduali e significativi, intervallati da periodi di stasi (spesso definiti ” inverni delle reti neurali “). Già nel 1943, prima ancora che esistessero i computer commerciali, McCulloch e Pitts iniziarono a esplorare come piccole reti di neuroni artificiali potessero imitare processi simili a quelli cerebrali. La natura interdisciplinare di questa ricerca pionieristica è evidente dal fatto che McCulloch e Pitts contribuirono anche al classico articolo di neurofisiologia “What the frog’s eye tells the frog’s brain” ( Lettvin et al., 1959); sorprendentemente, questo articolo non fu pubblicato su una rivista di biologia, bensì negli Atti dell’Istituto degli Ingegneri Radio .

Negli anni successivi, la crescente disponibilità di computer ha permesso di testare le reti neurali su semplici compiti di riconoscimento di pattern. Tuttavia, i progressi sono stati lenti, in parte perché la maggior parte dei finanziamenti per la ricerca era destinata ad approcci più convenzionali che non cercavano di imitare l’architettura neurale del cervello, e in parte perché i primi algoritmi di apprendimento delle reti neurali artificiali erano limitati. Una tassonomia delle reti neurali artificiali è mostrata nella Figura 1.
Il Perceptron
Una pietra miliare nella storia delle reti neurali è stata il percettrone di Frank Rosenblatt nel 1958, esplicitamente modellato sulle strutture neuronali del cervello. L’algoritmo di apprendimento del percettrone ha permesso a quest’ultimo di imparare ad associare input e output in un modo apparentemente simile all’apprendimento umano. Nello specifico, il percettrone poteva apprendere un’associazione tra un semplice input “immagine” e un output desiderato, dove quest’ultimo indicava se l’oggetto era presente o meno nell’immagine. Un semplice percettrone è mostrato nella Figura 2.
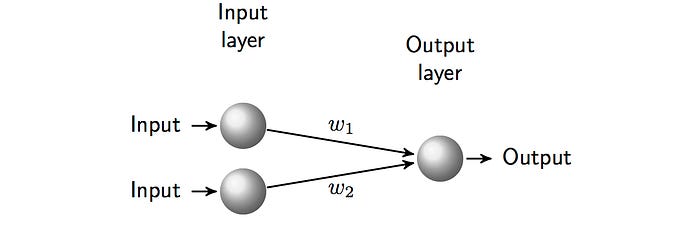
Reti neurali e memoria umana
I percettroni, e le reti neurali in generale, condividono tre proprietà chiave con la memoria umana. In primo luogo, a differenza della memoria convenzionale dei computer, la memoria delle reti neurali è indirizzabile per contenuto , il che significa che il richiamo viene attivato da un’immagine o da un suono, come mostrato nella Figura 3. Al contrario, la memoria dei computer può essere consultata solo se si conosce la posizione specifica (indirizzo) delle informazioni richieste.

In secondo luogo, un effetto collaterale comune della memoria indirizzabile per contenuto è che, data un’associazione appresa tra un’immagine di input e un output, il richiamo può essere attivato da un’immagine di input simile (ma non identica) all’input originale di una particolare associazione input/output. Questa capacità di generalizzare al di là delle associazioni apprese è una proprietà fondamentale, simile a quella umana, delle reti neurali artificiali.
In terzo luogo, se un singolo peso o un’unità viene distrutta, ciò non elimina alcuna associazione particolare; piuttosto, di solito degrada tutte le associazioni in una certa misura. Si ritiene che questa graduale degradazione assomigli alla memoria umana.
Il primo inverno delle reti neurali
Nonostante queste qualità simili a quelle umane, il percettrone subì un duro colpo nel 1969, quando Minsky e Papert dimostrarono, in un episodio diventato celebre, che non era in grado di apprendere associazioni a meno che non fossero di un tipo particolarmente semplice (ovvero linearmente separabili , come descritto nel Capitolo 2 di Artificial Intelligence Engines ). Questo segnò l’inizio del primo inverno delle reti neurali, durante il quale la ricerca in questo campo fu intrapresa solo da una manciata di scienziati. In questo periodo, le capacità delle reti lineari furono esplorate attraverso gli olofoni di Longuet-Higgins (1968), i correlografi di Longuet-Higgins, Willshaw e Buneman (1970) e le memorie a matrice di correlazione di Kohonen (1972).
Hopfield Networks
“La capacità di grandi gruppi di neuroni di svolgere compiti “computazionali” potrebbe essere in parte una conseguenza collettiva spontanea dell’avere un gran numero di neuroni semplici interagenti”.
JJ Hopfield, 1982.
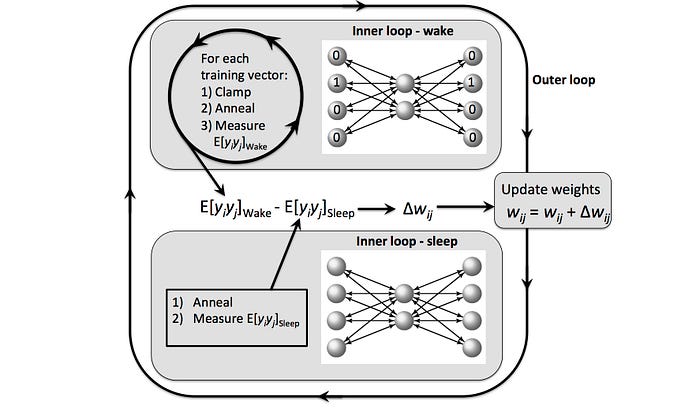
L’era moderna delle reti neurali è iniziata nel 1982 con la rete di Hopfield , mostrata in Figura 4. Sebbene le reti di Hopfield non siano molto utili nella pratica, Hopfield ha introdotto un quadro teorico basato sulla meccanica statistica , che ha gettato le basi per la macchina di Boltzmann di Ackley, Hinton e Sejnowki nel 1985.

La macchina di Boltzmann
“Studiando una macchina semplice e idealizzata che appartiene alla stessa classe generale di dispositivi computazionali del cervello, possiamo acquisire una comprensione dei principi che sono alla base del calcolo biologico.”
G. Hinton, T. Sejnowski e D. Ackley, 1984.
A differenza di una rete di Hopfield, in cui gli stati di tutte le unità sono specificati dalle associazioni che vengono apprese, una macchina di Boltzmann possiede un serbatoio di unità nascoste , che possono essere utilizzate per apprendere associazioni complesse, come mostrato nella Figura 5. La macchina di Boltzmann è importante perché ha facilitato un cambiamento concettuale, passando dall’idea di una rete neurale come macchina associativa passiva alla visione di una rete neurale come modello generativo .
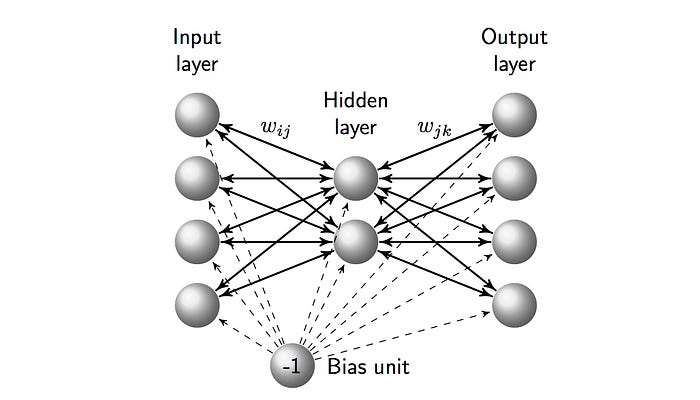
L’unico problema è che le macchine di Boltzmann apprendono a una velocità che si potrebbe definire glaciale (vedi Figura 6). Ma a livello pratico, la macchina di Boltzmann ha dimostrato che le reti neurali possono imparare a risolvere problemi complessi di tipo “giocattolo” (ovvero su piccola scala), il che suggerisce che potrebbero imparare a risolvere quasi qualsiasi problema (almeno in linea di principio, e almeno alla fine).
Reti neurali a retropropagazione
“Fino a poco tempo fa, l’apprendimento nelle reti multistrato era un problema irrisolto e considerato da alcuni impossibile.”
T. Sejnowski e C. Rosenberg, 1986.
L’impulso fornito dalla macchina di Boltzmann ha dato origine a un metodo più gestibile ideato nel 1986 da Rumelhart, Hinton e Williams, l’ algoritmo di apprendimento a retropropagazione . Una rete a retropropagazione è composta da tre strati di unità: uno strato di input, che è connesso tramite pesi di connessione a uno strato nascosto , il quale a sua volta è connesso a uno strato di output, come mostrato in Figura 7.
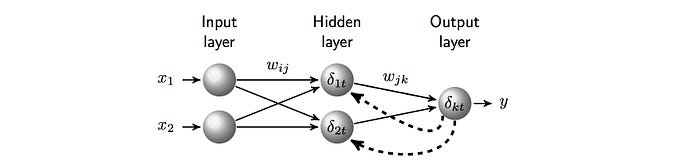
L’algoritmo di retropropagazione è importante perché ha dimostrato il potenziale delle reti neurali di apprendere compiti complessi in modo simile a quello umano. In particolare, per la prima volta, una rete neurale a retropropagazione chiamata NETtalk ha imparato a “parlare”, ovvero a tradurre il testo in fonemi (gli elementi base del linguaggio), che un sintetizzatore vocale ha poi utilizzato per produrre il parlato. Durante il processo di apprendimento, si affermò che NETtalk producesse output simili al balbettio dei neonati. Questo tipo di descrizione antropomorfica attirò molta attenzione da parte della stampa popolare dell’epoca.
Apprendimento per rinforzo
Parallelamente all’evoluzione delle reti neurali, l’apprendimento per rinforzo si è sviluppato negli anni ’80 e ’90, principalmente grazie a Sutton e Barto (2018). L’apprendimento per rinforzo è una fusione geniale tra il gioco simulato dai computer, come sviluppato da Shannon (1950) e Samuel (1959), la teoria del controllo ottimale e gli esperimenti stimolo-risposta in psicologia. Più recentemente, le reti di apprendimento profondo (vedi sotto) sono state utilizzate per potenziare i tradizionali algoritmi di apprendimento per rinforzo.
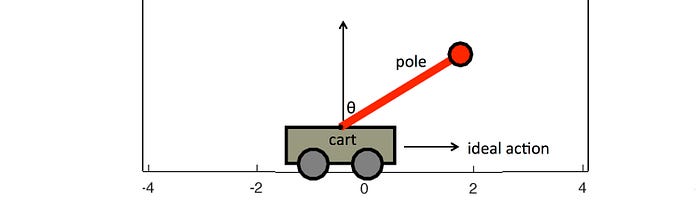
I primi risultati hanno dimostrato che problemi complessi, seppur di piccola scala (come bilanciare un palo, Figura 8), possono essere risolti utilizzando il feedback sotto forma di semplici segnali di ricompensa (Michie e Chambers, 1968; Barto, Sutton e Anderson, 1983). Più recentemente, l’apprendimento per rinforzo è stato combinato con il deep learning per produrre un’acquisizione di abilità impressionante, come nel caso di un aliante che impara a guadagnare quota sfruttando le correnti termiche (vedi Figura 9).

Inoltre, l’elenco delle applicazioni di successo dell’apprendimento per rinforzo nei giochi è impressionante. Queste applicazioni seguono le orme di un primo successo nel backgammon, noto come TD-Gammon (Tesauro, 1995), che avrebbe prodotto il miglior giocatore di backgammon del mondo (Sutton, 2018); le lettere TD stanno per differenza temporale, che è una componente dell’apprendimento per rinforzo . Un aspetto intrigante del TD-Gammon è che ha sviluppato uno stile di gioco innovativo, che è stato successivamente ampiamente adottato dai grandi maestri del gioco.
Nel 2016, AlphaGo ha sconfitto Lee Sedol, 18 volte campione del mondo di Go (Silver et al., 2016). Un anno dopo, AlphaGo ha battuto una squadra composta dai cinque migliori giocatori al mondo. Mentre AlphaGo inizialmente ha imparato osservando 160.000 partite umane, AlphaGo Zero ha imparato attraverso tentativi ed errori prima di battere AlphaGo 100 partite a zero (Silver et al., 2017). Sia AlphaGo che AlphaGo Zero si sono basati su una combinazione di apprendimento per rinforzo e apprendimento profondo.
Come TD-Gammon, AlphaGo Zero ha generato mosse inedite che hanno sorpreso e (inizialmente) sconcertato gli osservatori umani, ma che hanno portato a risultati positivi. Proprio come TD-Gammon ha modificato le strategie utilizzate dagli umani per giocare a backgammon, così AlphaGo Zero sta cambiando le strategie che gli umani usano per giocare a Go. Quindi, in un certo senso, gli umani stanno iniziando a imparare dalle macchine che imparano.
Già nel 1951 Alan Turing aveva previsto questi risultati:
“Una volta avviato il metodo di pensiero automatico, non ci vorrebbe molto perché superasse le nostre deboli capacità.”
A. Turing, 1951.
Considerate le parole preveggenti di Turing, forse non dovremmo sorprenderci dei risultati ottenuti dalle reti neurali. Ciononostante, l’importanza di AlphaGo Zero nel battere la macchina (AlphaGo) che ha sconfitto il campione del mondo umano non può essere sottovalutata. Potremmo tentare di razionalizzare i successi di AlphaGo Zero sottolineando che ha giocato molte più partite di quante un essere umano potrebbe mai giocarne in tutta la sua vita. Ma resta il fatto che un programma informatico ha imparato a giocare così bene da poter battere ognuno dei 7,7 miliardi di persone sul pianeta. Statisticamente parlando, questo colloca AlphaGo Zero al di sopra del 99,9999999° percentile in termini di prestazioni.
Dalla retropropagazione al deep learning
In teoria, una rete backpropagation con soli due strati nascosti di unità può associare praticamente qualsiasi input a qualsiasi output, il che significa che dovrebbe essere in grado di svolgere la maggior parte dei compiti. Tuttavia, far sì che una rete backpropagation impari i compiti che dovrebbe essere in grado di svolgere in teoria è problematico. Una soluzione plausibile è aggiungere più unità a ciascun strato e più strati di unità nascoste, perché questo dovrebbe migliorare l’apprendimento (almeno in teoria). In pratica, si è scoperto che le reti backpropagation convenzionali faticavano ad apprendere se avevano architetture di deep learning come quella mostrata nella Figura 10.

Con il senno di poi, il campo dell’intelligenza artificiale trae origine dalla ricerca originariamente condotta sulle reti di Hopfield, le macchine di Boltzmann, l’algoritmo di retropropagazione e l’apprendimento per rinforzo. Tuttavia, l’evoluzione delle reti di retropropagazione in reti di apprendimento profondo ha dovuto attendere tre sviluppi correlati: 1) computer molto più veloci, 2) set di dati di addestramento enormemente più grandi e 3) miglioramenti incrementali negli algoritmi di apprendimento.
È difficile quantificare con precisione quanto ciascuno di questi sviluppi abbia contribuito al rapido ritmo di progresso degli ultimi anni (Sejnowski, 2018). Qualunque sia la causa esatta, considerando le enormi risorse attualmente allocate alla ricerca sulle reti neurali da governi e industria, sembra probabile che l’ ultimo inverno delle reti neurali sia ormai finito.
Nota: questo è un estratto modificato da Artificial Intelligence Engines di James V Stone. Inevitabilmente, non tutti i contributori al campo delle reti neurali artificiali possono essere inclusi in un breve riassunto come questo. Per una panoramica storica più dettagliata, si prega di consultare la sezione “Letture consigliate” qui di seguito.
Anche di James V Stone La nuova IA dell’imperatore?
Leggi anche
Riferimenti
Barto, AG, Sutton, RS e Anderson, CW. Elementi adattivi simili a neuroni in grado di risolvere difficili problemi di controllo dell’apprendimento. IEEE Trans. Sys. Man Cyb., 13(5):834–846, 1983.
Hinton, GE, Sejnowski, TJ e Ackley, DH. Macchine di Boltzmann: reti di soddisfacimento dei vincoli che apprendono. Rapporto tecnico, Dipartimento di Informatica, Università Carnegie-Mellon, 1984.
Hopfield, JJ. Reti neurali e sistemi fisici con capacità computazionali collettive emergenti. Proc. Nat. Acad. Sci. USA, 79(8):2554–2558, 1982.
Kohonen, T. Memorie a matrice di correlazione. IEEE Trans. Computers, 100(4):353–359, 1972.
Lettvin, JV, Maturana, HR, McCulloch, WS e Pitts, WH. Cosa dice l’occhio della rana al cervello della rana. Atti dell’Istituto degli Ingegneri Radio, pagine 1940–1951, 1959.
Longuet-Higgins, HC. L’immagazzinamento non locale delle informazioni temporali. Proc. R. Soc. Lond. B, 171(1024):327–334, 1968.
Longuet-Higgins, HC, Willshaw, DJ e Buneman, OP. Teorie del ricordo associativo. Quarterly Reviews of Biophysics, 3(2):223–244, 1970.
McCulloch, WS e Pitts, W. Un calcolo logico delle idee immanenti nell’attività nervosa. Bull. Math. Biophysics, 5:115–133, 1943.
Michie, D e Chambers, RA. BOXES: Un esperimento di controllo adattivo. Machine Intelligence, 2(2):137–152, 1968.
Minsky, M e Papert, S. Perceptron: un’introduzione alla geometria computazionale. MIT Press, 1969.
Rosenblatt, F. Il percettrone: un modello probabilistico per l’immagazzinamento e l’organizzazione delle informazioni nel cervello. Psychological Review, 65(6):386– 408, 1958.
Rumelhart, DE, Hinton, GE e Williams, RJ. Apprendimento di rappresentazioni tramite errori retropropaganti. Nature, 323:533–536, 1986.
Samuel, AL. Alcuni studi sull’apprendimento automatico utilizzando il gioco della dama. IBM Journal of Research and Development, 3(3):210–229, 1959.
Sejnowski, TJ e Rosenberg, CR. NETtalk. Sistemi complessi, 1(1), 1987.
Sejnowski, TJ. La rivoluzione del deep learning. MIT Press, 2018.
Shannon, CE. Programmazione di un computer per giocare a scacchi. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, 41(314):256–275, 1950.
Silver, D et al. Padroneggiare il gioco del Go con reti neurali profonde e ricerca ad albero. Nature, 529:484–503, 2016.
Silver, D et al. Padroneggiare il gioco del Go senza l’aiuto di conoscenze umane. Nature, 550(7676):354–359, 2017.
Sutton, RS e Barto, AG. Apprendimento per rinforzo: un’introduzione. MIT Press, 2018.
Tesauro, G. Apprendimento della differenza temporale e TD-Gammon. Communications of the ACM, 38(3):58–68, 1995.
Leggi anche
Ulteriori letture
Sejnowski, TJ. La rivoluzione del deep learning. MIT Press, 2018. Questo libro offre una storia personale, raccontata da uno scienziato che ha svolto un ruolo fondamentale nello sviluppo degli algoritmi delle reti neurali.